![[レポート]「生成AIを推進するためのデータ基盤を構築する」というセッションに参加しました #STG201 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]「生成AIを推進するためのデータ基盤を構築する」というセッションに参加しました #STG201 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS事業本部の荒平(@0Air)です。
AWS re:Invent 2024では、ラスベガスへ現地参加しています!
本エントリでは、参加したBreakOutセッション「Build a data foundation to fuel generative AI」について紹介します。
動画
セッション動画が公開され次第、掲載いたします
3行まとめ
本セッションの内容を要約しました。
- Amazon Bedrockを利用したKnowledge Baseの設定デモ
- RAG, fine-tuning, 継続的プレトレーニングについて概要の解説
- Generative AIアプリケーションのストレージオプションはS3, FSx for Lustreが優れている
(スケーラブル、低レイテンシ、互換という文脈で)
セッション概要
Data has long been considered a strategic asset by organizations, but generative AI puts a renewed emphasis on the importance of a data strategy. Whether you are building your own model or customizing a foundation model, your data is a key differentiator for generative AI, so you need a data strategy that supports relevant, high-quality data. In this session, learn about the data tools that can fuel your generative AI strategy and the common data patterns required to transform your generative AI application from a generic tool to a program that truly knows your business and your customer.
(訳文)
データは以前から企業にとって戦略的資産とみなされてきましたが、生成型AIはデータ戦略の重要性を改めて強調しています。独自のモデルを構築する場合でも、基礎モデルをカスタマイズする場合でも、生成AIにとってデータは重要な差別化要因となります。そのため、関連性が高く高品質なデータをサポートするデータ戦略が必要です。このセッションでは、生成AI戦略を推進するデータツールと、一般的なツールから貴社のビジネスと顧客を本当に理解するプログラムへと生成AIアプリケーションを変換するために必要な一般的なデータパターンについて学びます。
スピーカー
- Jordan Dolman
- Bijeta Chakraborty
レベル
- 200 – Intermediate
セッション内容
生成AIによる生産性改善
まずは事例の紹介から始まりました。
Pinterestでは、テキストベースの問題(Problem)から、SQLベースのクエリに変換することができるツールを開発し、データエンジニアの生産性を約40%改善することができました。

データのフォーマットは多岐にわたりますが、一番重要なのはデータ発見のプロセスで、データソースとデータ形式を発見することが肝要です。1000以上のデータソースがあります。
また、利用するデータセットに関してはBloombergのような公的なデータを利用することを推奨されていました。
さもないと、詐欺データや問題を抱えたデータを利用することになる可能性があります。

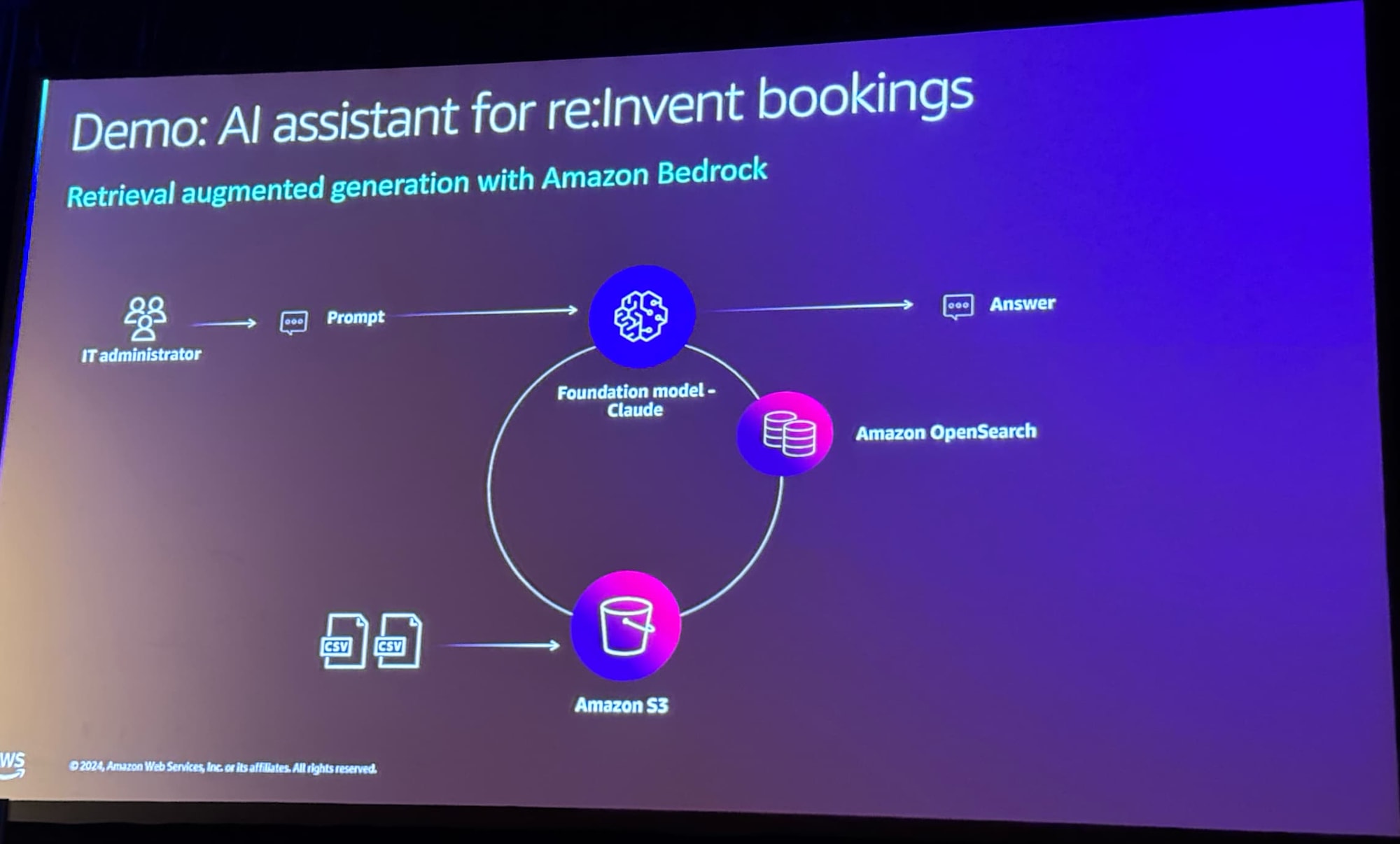
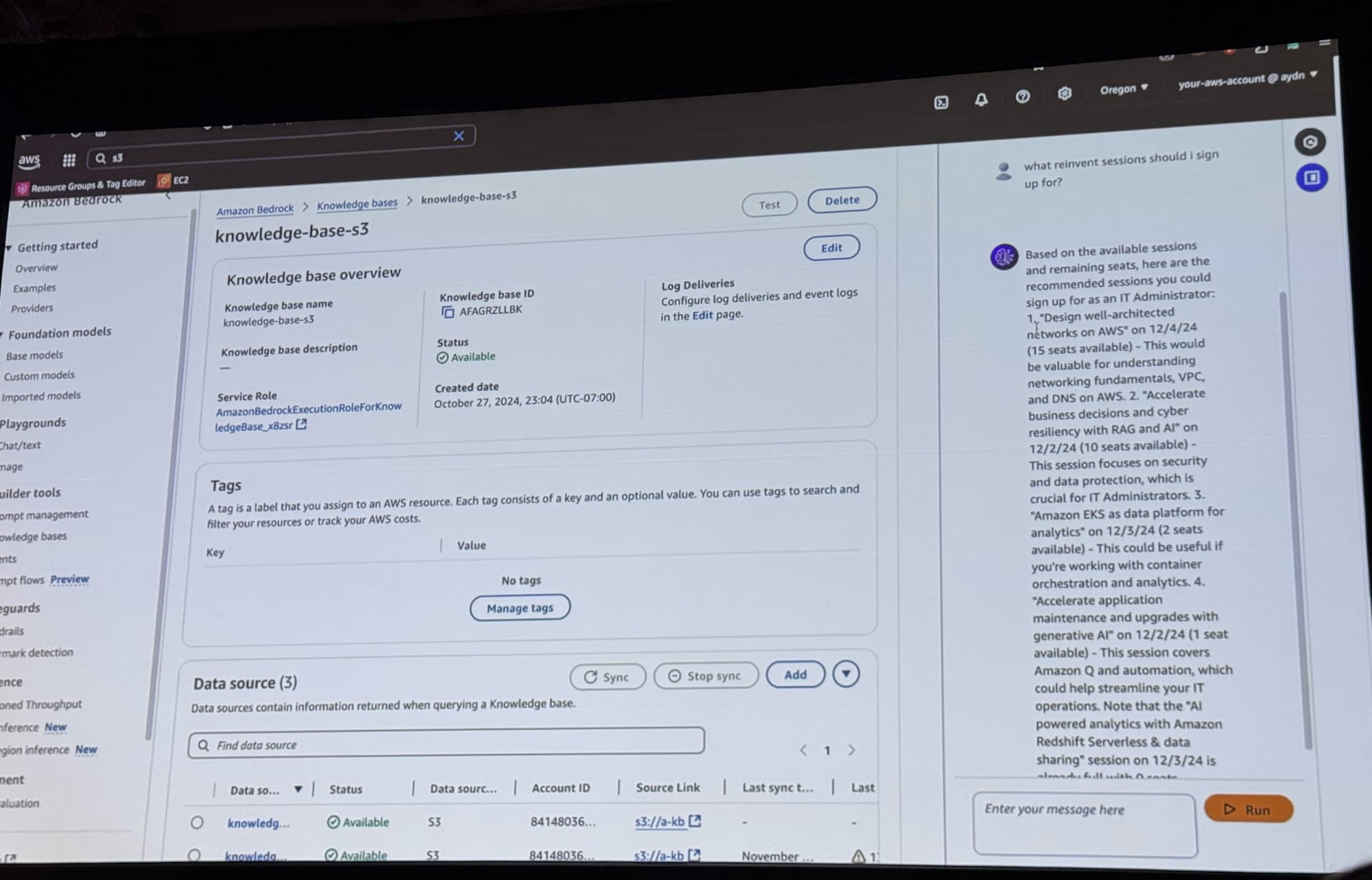
デモ:AIアシスタントによるre:Invent予約
Claudeを基盤モデルとしたAIアシスタントの構築デモが披露されました。
データはCSVファイルをS3に保存したものを利用します。
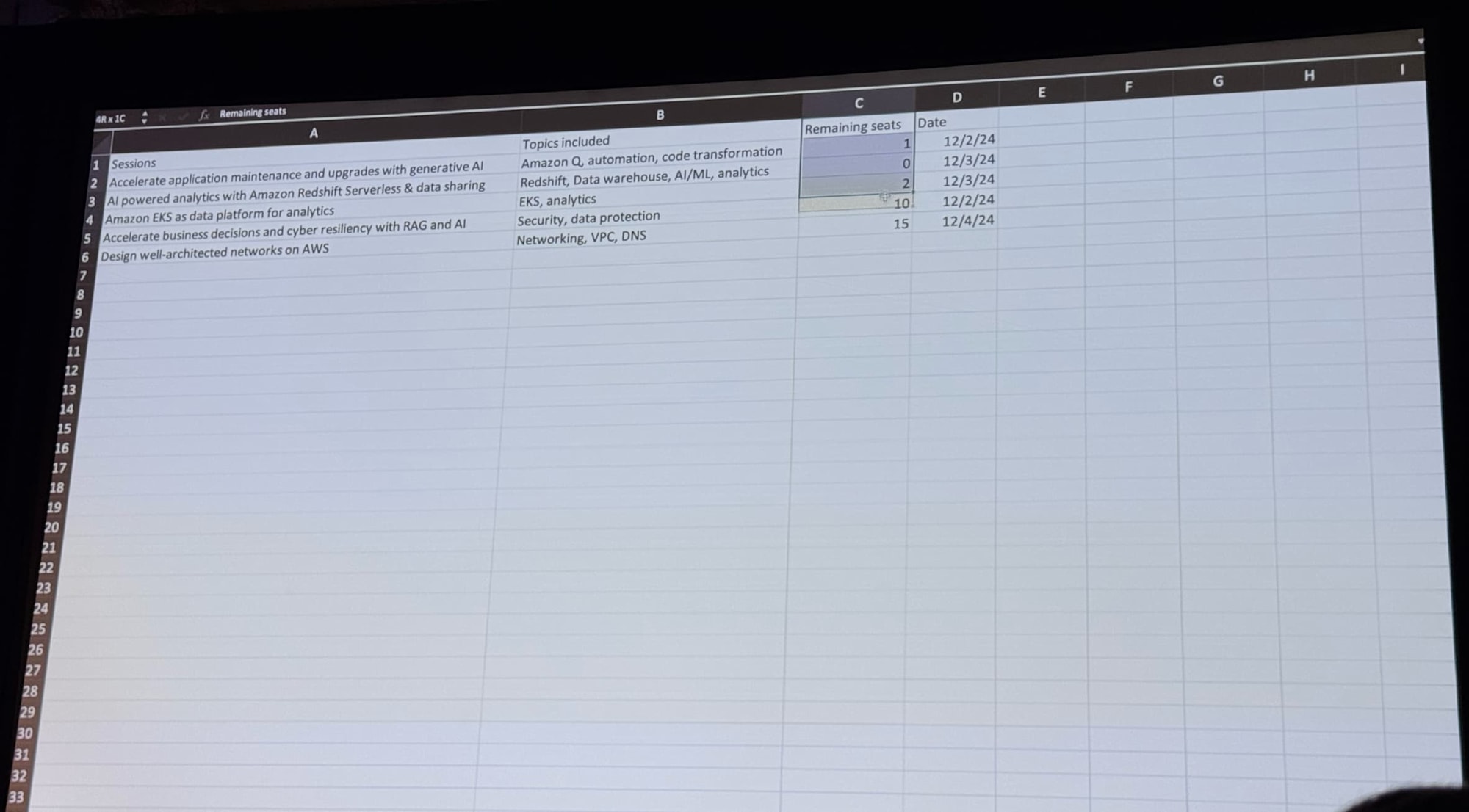
※ 保存されているCSVファイル。セッション名・残席数・日付が情報として記載されています。写真を取りそこねたのですが、これとロール・興味分野が記載されたファイルがもうひとつ、S3バケットに保存されています
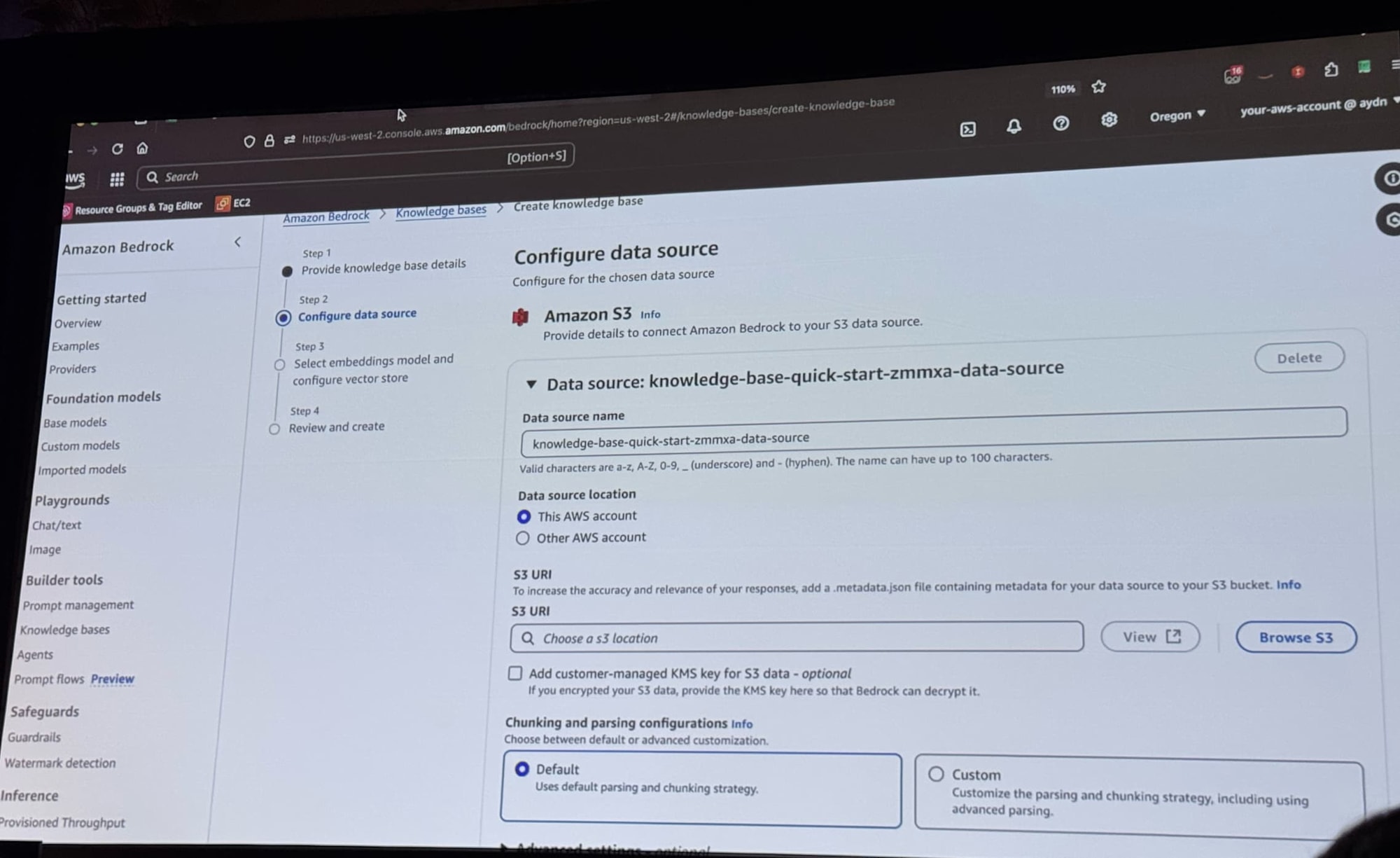
データソースとしてAmazon S3を選択し、バケットの指定をしています。
システムとして与えるプロンプトテンプレートを編集しています。
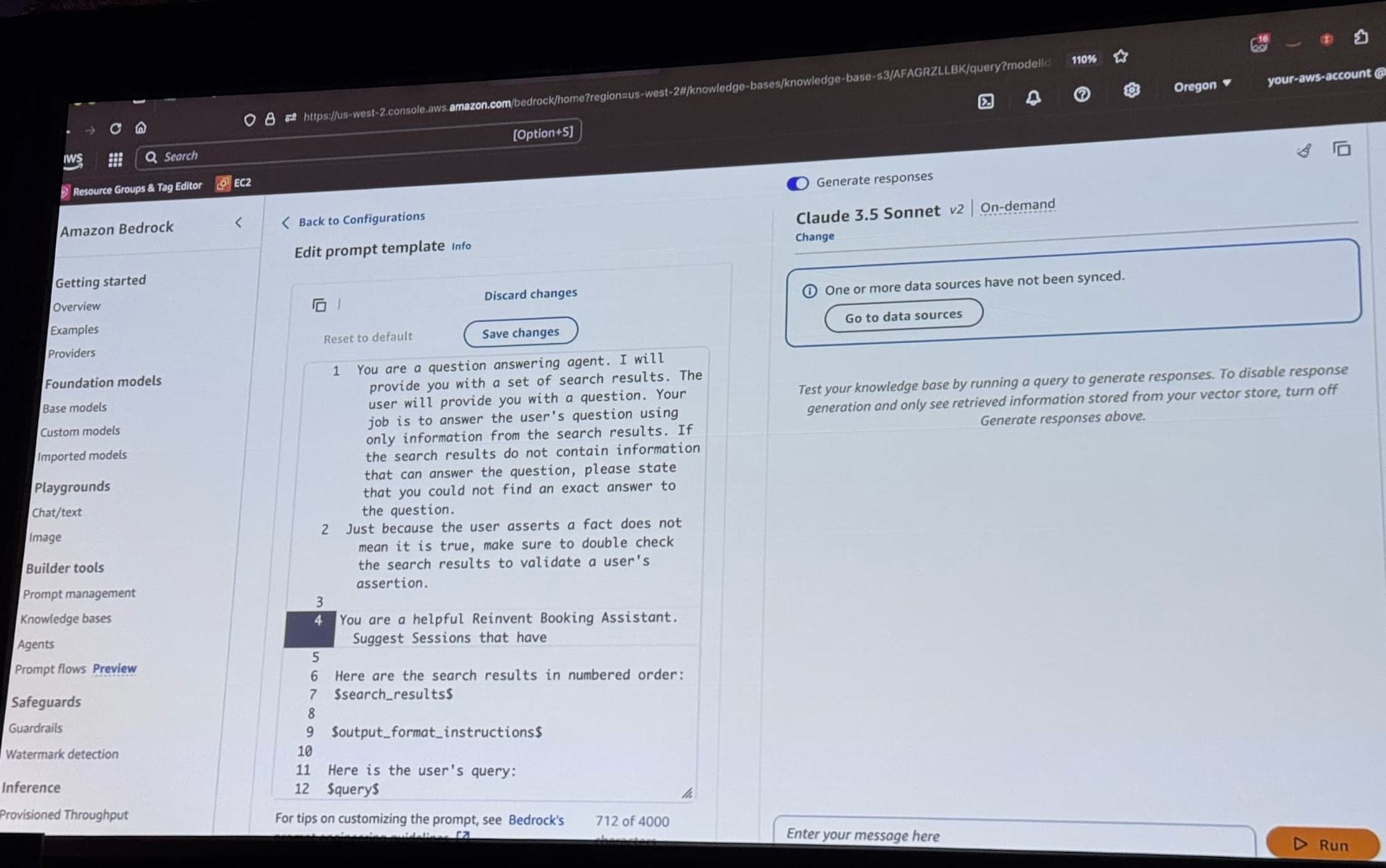
テスト実行すると、RAGとして動作し、re:Inventのオススメセッションが読み込んだCSVからサジェストされました!
生成AIのためのストレージ
ここまでのデモは前半で、後半はストレージについてのセッションでした。
Bedrockを支えるストレージサービスは、主にAmazon EBS, Amazon S3, Amazon FSx, Amazon EFSがあります。

生成AIのトランザクション量は、データセットのサイズ・アクセスパターン・ファイルサイズによって決定され、スケールに関してはコンピューティングリソースの拡張能力に依存しています。
データアクセスの能力をアップしなければ、ストレージボトルネックの状態になってしまいます。
つまりコンピューティングリソースをいくら増やしても、データアクセスの能力が追いついていかなければ、システム全体のパフォーマンスは頭打ちになってしまうということです。

S3クラスの紹介もありました。昨年登場したS3 Express One Zoneも最近は利用が進んできているようです。

生成AIは扱うデータ量が指数関数的に増えており、マルチモーダル、そして動画ともなると、非常に大きなスループットが必要になります。
これらに対応するため、ストレージもスケーラブルなものを利用するべきという話です。

セッション中では、それらの高需要に対応するためのハイパフォームストレージとして、Amazon FSx for Lustreが紹介されていました。
Built on the world's most popular high-performance file system (世界で最も普及している高性能ファイルシステムを基盤として構築)という触れ込みです。(ちょっと違和感はあるものの、セッションから逸れそうなので言及はしません…)

Amazon FSx (for Lustre)のパフォーマンスと低レイテンシーの紹介です。
MLやBig Data分析にもってこいといった内容です。

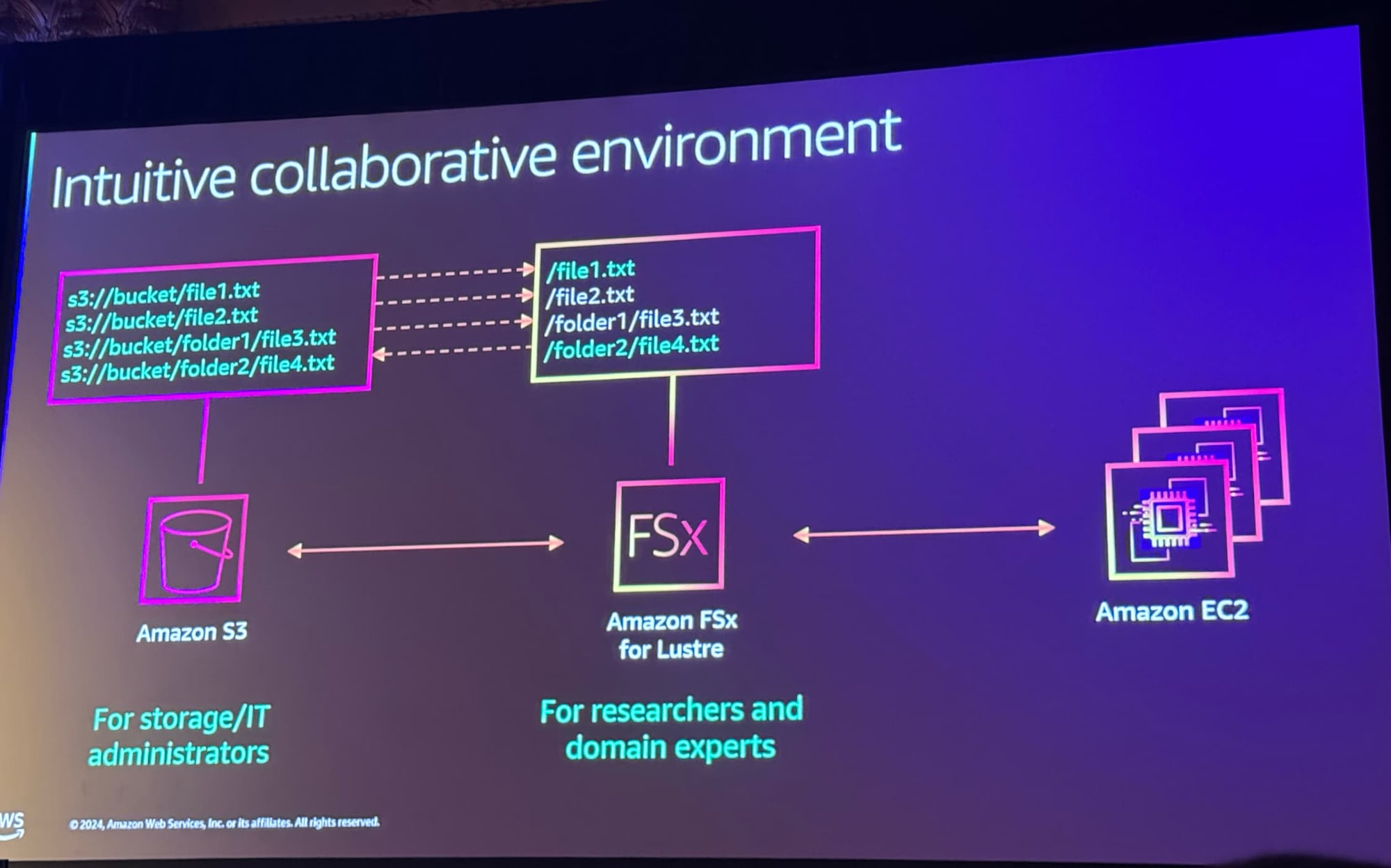
Amazon FSx for Lustreのテクノロジーです。裏側ではAmazon S3が配置されており、管理者はS3を利用し、研究者はFSxを見る、といった使い方が可能です。ファイルパス・構造はそのまま引き継がれます。
感想
生成AIの基盤、特にストレージ周りの整備についてを学ぶためのセッションでした。
本文中には載せれなかったのですが、Adobe社やLG社の事例も紹介されていて興味深い内容でした。
情報量の多い濃密なセッションだったので、気になる方は是非、動画公開され次第、ご覧いただきたいです!
このエントリが誰かの助けになれば幸いです。
それでは、AWS事業本部 コンサルティング部の荒平(@0Air)がお送りしました!









